Author: Dr Adrian Bermudez-Villalva (adriano.bermudezvillalva@rhul.ac.uk)
In the field of cybersecurity research, gathering data from social media platforms has become an essential task for understanding various trends, behaviours, and patterns on the internet. However, when it comes to sensitive and intimate topics such as women’s health and misinformation, researchers face a multitude of challenges in extracting relevant data from popular platforms like Facebook, Twitter, and Reddit [1]. In this blog post, we will explore the difficulties researchers encounter and the limitations imposed by the social media giants, which hinder their efforts to acquire valuable data.
Facebook: Restricted API and Crawler Roadblocks
Being one of the largest social media platforms, Facebook poses significant challenges for researchers trying to access public posts containing content regarding topics such as women’s health such as abortion. The primary obstacle is the restrictive nature of Facebook’s API (Application Programming Interface), which severely limits the type of data that can be extracted from the platform.
To bypass the limitations of the API, some researchers resort to web crawling methods, often utilising tools like Selenium to extract data from Facebook. While this approach seems promising, it comes with its own set of difficulties:
1. Account Blocking: Facebook employs stringent anti-scraping measures to protect user privacy and platform integrity. As a result, researchers who create dedicated accounts for web crawling purposes are likely to encounter account blocks and restrictions due to the platform’s automated security measures.
2. Account Verification: The process of creating multiple Facebook accounts for data extraction is further complicated by the mandatory verification requirements, which involve phone numbers and other personal information. This makes it challenging for researchers to create the necessary number of accounts for their studies.
3. Dynamic Website Elements: Facebook’s web interface is highly dynamic, relying heavily on JavaScript to generate and display content. Consequently, web crawlers built with Selenium or other tools often struggle to locate and extract the required data consistently, as the website structure may change frequently [2].
4. Ethical and Legal Considerations: While web scraping itself might not be illegal, scraping Facebook’s data can raise ethical and legal questions, as it involves accessing user-generated content without explicit consent from all parties involved [3].
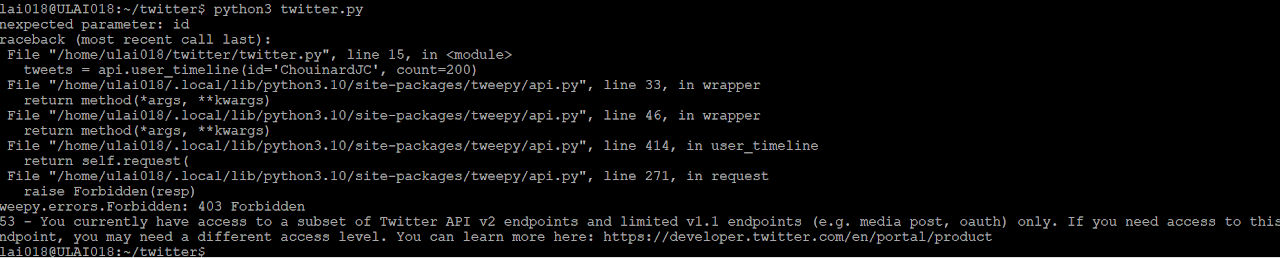
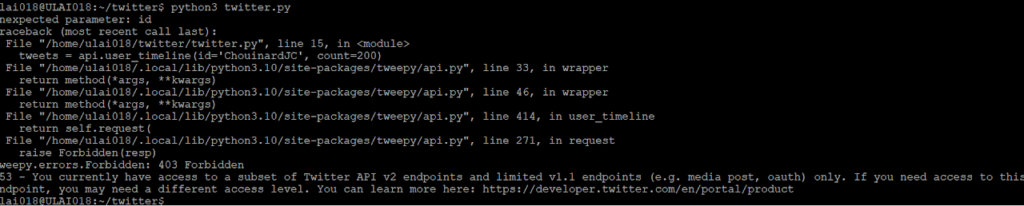
Twitter: Limited API Access for Researchers
Twitter, another prominent platform, has historically provided academic researchers with access to its API, allowing them to collect valuable data for various studies, including those related to misinformation. However, the landscape has changed, and researchers now face significant obstacles:
1. API Restrictions: Twitter’s API access for academic researchers has been severely limited, leaving researchers with reduced access to public posts and historical data [4]. As a result, studies focusing on timely topics such as intimate health and women’s health misinformation may face data scarcity and incompleteness.
2. Challenges in Data Collection: The limited API access hinders researchers’ ability to gather real-time data from Twitter, which can be crucial for tracking and analysing the rapid spread of misinformation.
3. Lack of Data Granularity: With restricted API access, researchers may struggle to obtain detailed information such as user demographics, retweet networks, and engagement metrics, limiting the depth of analysis possible.
Reddit: Ephemeral Nature of Intimate Health and Misinformation
Reddit is a popular platform with various subreddits dedicated to discussions on intimate topics such as women’s health. However, extracting misinformation content from Reddit poses unique challenges:
1. Content Moderation: Reddit’s content moderation is a combination of actions taken by both a combination of human central administrators, automated programs and community users [5]. As a result, posts containing misinformation related to women’s health are swiftly removed within seconds or minutes after publication, making it extremely challenging to capture such content for research purposes.
2. Transparency and Access: Reddit’s API provides limited access to historical data, and the platform does not offer a comprehensive way to retrieve deleted posts. This lack of transparency hinders researchers from gaining insights into the spread and impact of misinformation over time.
Conclusion: The Uphill Battle for Researchers
As cybersecurity researchers in academia, the pursuit of knowledge about intimate health and other sensitive topics such as misinformation related to vaccine and women’s health on social media platforms is key to develop countermeasures to tackle this issue. However, the challenges imposed by restricted APIs, web crawling complexities, and limitations in historical data access have turned this endeavour into an uphill battle. To bridge the gap between cybersecurity research and understanding the nuances of misinformation, it is imperative for social media platforms to collaborate with academic institutions, facilitating responsible access to data and fostering a culture of open and transparent research.
As we move forward, it is crucial for researchers, policymakers, and social media platforms to work together to find ethical and sustainable solutions that empower researchers to explore the intricate landscape of misinformation and ultimately contribute to a safer and more informed online environment.
If you are an active researcher in this field and have expertise and experience to offer, please get in touch via emailing Adrian (adriano.bermudezvillalva@rhul.ac.uk).
For more information on this topic, please visit CyFer: Cyber Security, Privacy, Trust and Bias in FemTech
References
1. Stieglitz, S., Mirbabaie, M., Ross, B., & Neuberger, C. (2018). Social media analytics–Challenges in topic discovery, data collection, and data preparation. International journal of information management, 39, 156-168.
2. Deen Freelon (2018) Computational Research in the Post-API Age, Political Communication, 35:4, 665-668, DOI: 10.1080/10584609.2018.1477506.
3. Mancosu, M., & Vegetti, F. (2020). What You Can Scrape and What Is Right to Scrape: A Proposal for a Tool to Collect Public Facebook Data. Social Media + Society, 6(3).
4. Davidson BI, Wischerath D, Racek D, et al. Social Media APIs: A Quiet Threat to the Advancement of Science. PsyArXiv; 2023.
5. Shagun Jhaver, Iris Birman, Eric Gilbert, and Amy Bruckman. 2019. Human-Machine Collaboration for Content Regulation: The Case of Reddit Automoderator. ACM Trans. Comput.-Hum. Interact. 26, 5, Article 31 (October 2019), 35 pages.