AI-Generated Content Detection
Disinformation: Knowledge Repository
AI-Generated Image Detection for Misinformation Handling
Recent advancements in generative models have revolutionised the creation of photo-realistic images, making it faster, cheaper, and more accessible than ever before. Techniques such as Generative Adversarial Networks (GANs) and diffusion models have enabled unprecedented realism in synthetic images, reshaping industries from entertainment to advertising. Moreover, with readily accessible, pre-trained text-to-image models, like DALL-E, MidJourney, and Stable Diffusion, have made it easier to generate high-quality synthetic images. Various examples of images that recently attracted a lot of public attention demonstrate how these synthetic creations increasingly blend with natural images, leading to two key types of misidentifications: synthetic images being mistaken for natural ones and natural images being misclassified as synthetic.
We emphasise the need for feature-sensitive training paradigms that preserve subtle artefacts and employ diverse augmentation techniques to bridge distributional disparities between training and testing data. By investigating the interplay between universal artefact features and training methodologies, our work contributes to the development of robust AI-generated image detection (AGID) systems capable of adapting to the rapidly evolving landscape of generative models.
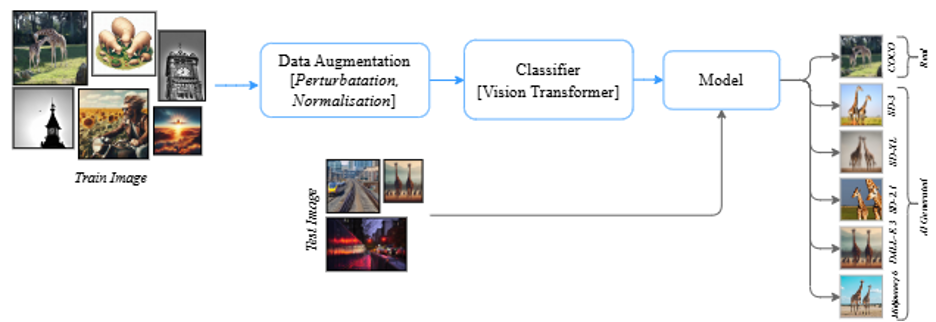
Our pipeline, illustrated in the above Figure, outlines our systematic approach for training and testing a classification model designed to differentiate between real images and those generated by AI models. The framework comprises two stages, training and testing, each utilising distinct image preprocessing steps. During the training, the pipeline uses a pre-trained Vision Transformer (ViT) architecture that is then fine-tuned on the provided training dataset, while testing uses the trained model to classify into the various classes. To make the model robust to various image distortions, we opted to include several transformations in the training pipeline. By training on augmented data, the model learns to generalise to distorted inputs. The following augmentations are employed:
- Colour Jittering: Random brightness adjustments in the range of 0.45-0.55 introduce variability in pixel intensities.
- Random Horizontal/Vertical Flips: Probabilistic mirroring of images to increase sample diversity.
- JPEG Compression: Images are subjected to compression with a quality range of 30-70 to simulate real-world compression noise.
- Random Rotation: Images are randomly rotated within the range of 0-90 degrees to introduce perspective variations.
- Gaussian Noise: Additive noise with mean 0 and standard deviation up to 0.3 is applied to simulate sensor noise.
- Random Crop: Images are cropped and resized within a predefined range to simulate different zoom levels and perspectives.
Our pipeline was evaluated on the validation and test sets of the Defactify 4.0 – CT2 – AI-generated image detection challenge which focused on two tasks: (i) Task A – Binary classification task where the goal is to determine whether each given image was generated by AI or created by a human. (ii) Task B – Multi-class classification task where the goal is to identify whether the images were produced by models such as SD 3, SDXL, SD 2.1, DALL-E 3, or Midjourney 6. Our method achieved a validation F1-score of 0.9963 and 0.9839 for Task A and Task B respectively on the validation set and we obtained an F1 score of 0.8292 and 0.4864, respectively, on the testing leaderboard. These results underscore the effectiveness of ViT in extracting fine-grained features essential for distinguishing real and AI-generated content.
More details in the related outputs
Shrikant Malviya, Bhowmik, N., and Stamos Katsigiannis. 2025. SKDU at De-Factify 4.0: Vision Transformer with Data Augmentation for AI-Generated Image Detection. In Proceedings of the De-factify 4.0 Workshop, 39th Annual AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA. https://durham-repository.worktribe.com/output/3488967
AI-Generated Text Detection for Misinformation Handling
The rapid advancements in large language models (LLMs) have revolutionised natural language processing (NLP), enabling systems to generate human-like text with remarkable fluency and contextual relevance. These models, such as OpenAI’s GPT-3.5, GPT-4, and Meta’s LLaMA, are now widely used across various domains, including education, customer support, and creative content generation. While these systems have demonstrated significant potential to augment human productivity and assist in a variety of tasks, they also introduce critical challenges, particularly in ensuring their responsible use.
One major concern is the misuse of LLMs for generating misleading or harmful content. Malicious actors can exploit these models to create misinformation, spam, or fraudulent websites, leveraging their ability to produce seemingly credible and factually sound text at scale. Compounding the issue, these models often present information with high fluency and confidence, which can deceive users into mistaking coherence for truthfulness. Inexperienced users may unknowingly rely on AI-generated text for high-stakes tasks, such as academic writing or medical advice, only to encounter significant inaccuracies or unintended consequences. This raises concerns about the ethical and safe deployment of these powerful systems in everyday applications.
We investigate the task of identifying AI-generated text, focusing on evaluating features such as geneRative AI Detection viA Rewriting (RAIDAR), content-based features from the News Landscape (NELA) toolkit, e.g., stylistic features (stopwords, punctuation, quotes, negations etc), complexity features (type-token ratio, words per sentence, noun/verb phrase syntax tree depth), psychology features (linguistic inquiry and word count, positive and negative emotions). The findings of this research provide critical insights into the differences between human- and AI-generated text, offering valuable guidance for improving detection frameworks.
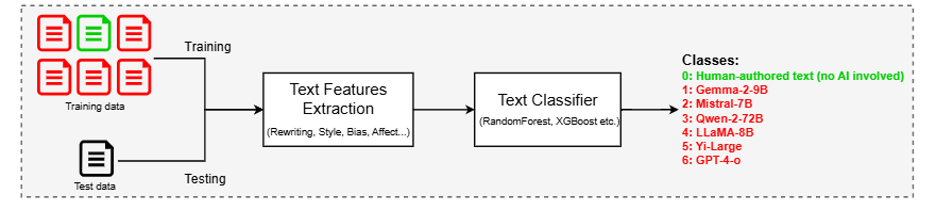
Our methodology follows a systematic pipeline for training and testing, as depicted in the Figure above. The pipeline ensures a clear flow from input text to final predictions, with well-defined stages for feature extraction, fusion, and classification. Our feature extraction approach combines rewriting-based techniques and NELA features to capture diverse linguistic and stylistic attributes. Inspired by the RAIDAR framework, we adopt a rewriting approach to detect AI-generated text. The rewriting for a given text is done based on 7 different prompts. For prompting, we use the meta-llama/Llama-3.1-8B model for generating rewritings due to its balance between computational efficiency and generative capabilities. The underlying intuition is that human-written and AI-generated text respond differently to perturbations in the form of rewriting. This step highlights structural and stylistic differences based on rewriting features. In parallel, NELA features contribute lexical, stylometric, and content-based attributes, such as word frequencies, readability scores, sentiment analysis, and entity recognition. A set of 87 stylistic, complexity, and psychological attributes are extracted and used as features. By integrating these two methodologies, we ensure the extraction of both fine-grained and broad textual features, enhancing the ability to distinguish between human-written and AI-generated text. The extracted features are then used to train a text classifier.
Our methodology was evaluated on the validation and test sets of the Defactify 4.0 – CT2 – AI-generated text detection challenge which focused on two tasks: (i) Task A – Binary classification task where the goal is to determine whether each given text document was generated by AI or created by a human. (ii) Task B – Multi-class classification task where the goal is to identify which specific LLM generated a given piece of AI-generated text. Results showed that using the NELA features and the XGBoost classifier consistently outperformed other combinations of feature sets and classifiers, achieving F1 scores of 0.9979 and 0.8489 on Task-A and Task-B respectively for the development set, as well as F1 scores of 0.9945 and 0.7615, respectively, on the testing leaderboard. Our results highlight the importance of selecting high-quality, discriminative features and avoiding redundancy in detection frameworks.
More details in the related outputs
Shrikant Malviya, Pablo Arnau-González, Miguel Arevalillo-Herráez, and Stamos Katsigiannis. 2025. SKDU at De-Factify 4.0: Natural language features for AI-Generated Text-Detection. In Proceedings of the De-factify 4.0 Workshop, 39th Annual AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA. https://durham-repository.worktribe.com/output/3488998




